データベースとは?
データベースとは、データを体系的に整理・保存し、効率的にアクセス・管理するための構造化された情報の集合体を指します。データベース(英:Database・DB) は、様々なデータを一元管理し、必要に応じて情報を迅速かつ正確に取得するための基盤として機能します。
データベースは、日常生活からビジネスの様々な場面において、情報の整理・管理・利用を支援する重要なツールです。例えば、オンラインショッピングサイトの製品カタログ、病院の患者記録、企業の財務データ、学校の成績管理システムなど、多岐にわたる分野で利用されています。
データベース管理システム (DBMS) は、データベースの作成、管理、および操作を行うためのソフトウェアであり、データベースの効率的な運用を支援します。DBMSには、Oracle、MySQL、PostgreSQL、Microsoft SQL Serverなどの様々な種類があります。各DBMSは、それぞれ異なる機能や特徴を持ち、用途やニーズに応じて選択されます。
データベースの基本的な特徴
- データの整理と構造化: データはテーブルやフィールドなどの構造に整理されます。これにより、関連するデータを効率的に保存・取得することができます。
- データの一貫性と整合性: データベースシステムはデータの一貫性を保つためのルールや制約を設定できます。これにより、データの正確性と信頼性が向上します。
- アクセスの効率化: データベースは検索やフィルタリングのための機能を提供し、必要なデータを迅速に見つけ出すことができます。
- 同時アクセスと共有: 複数�のユーザーが同時にデータベースにアクセスし、データを共有することができます。これにより、チームや組織内での情報共有が容易になります。
- セキュリティとバックアップ: データベースはアクセス権の管理やデータのバックアップ機能を提供し、データの安全性を確保します。
Lucidchartやエクセルなどのデータベース ツールを使用することで、データベースの設計を視覚的に行い、効率的なデータベース構築が可能になります。データベース設計の基本を理解し、実際にデータベースを作成してみることで、データ管理のスキルを向上させましょう。
データベースの種類一覧
データベースにはさまざまな種類があります。最も一般的なモデルには以下のものがあります。
- 階層型データベースモデル
- 関係モデル
- ネットワークモデル
- オブジェクト指向データベースモデル
- 実体関連モデル
- ドキュメント型モデル
- エンティティ-アトリビュート-バリューモデル
- スタースキーマ
- オブジェクト関係モデル
データベースを記述するモデルの選択は、いくつかの要因に基づいて行います。最大の要因は、使用しているデータベース管理システム(DBMS)が特定のモデルに対応しているかどうかです。複数のモデルに対応するDBMSもありますが、大半のDBMSは特定のデータモデルを念頭に設計されています。その場合、その特定のモデルを使用する必要があります。
また、DB設計プロセスの各段階に応じて異なるモデルを使用することもあります。例えば、ユーザーがデータを知覚する方法でデータ間の関連を図式化するには、高次的な概念データモデルが最適です。他方で、レコードに基づく論理モデルでは、サーバーにデータを格納する方法をより正確に記述できます。
さらに、データモデルを選択する際には、速度、コスト削減、利便性など、データベースに求める優先順位と特定のモデルの強みを考慮することも重要です。
それでは、最も一般的なデータベースモデルのいくつかを詳しく比較してみましょう。
関係データベース
関係モデル
最も一般的なデータベースモデルである関係モデルでは、データを行と列で構成される表(リレーション)に並べ替えます。各列には、価格、郵便番号、生年月日など、エンティティの属性が示されます。このような属性の集まりをドメインと呼びます。特定の属性やその組み合わせを主キーとして選択し、主キーは他の表で外部キーとして参照されます。
各行(タプル)には、特定の従業員など、エンティティの特定のインスタンスに関するデータが含まれます。
このモデルは、一対一、一対多、多対多といったテーブル間の関連性も表現できます。以下に例を示します。

関係データベース内では、テーブルを正規化し、データベースの柔軟性、適応性、スケーラビリティを確保するために正規化ルールを適用します。テーブルを正規化すると、データが最小単位に分解され、各部分が不可分となります。
関係データベースは一般に構造化照会言語(SQL)で記述されます。このモデルはエドガー・F・コッドによって1970年に発表されました。
階層モデル
階層モデルでは、各レコードが1つの親(ルート)を持つ木構造のようにデータを整理します。兄弟レコードは特定の順序で並べられ、その順序はデータベースに格納される物理的な順序として使用されます。この関係データベースモデルは、世界の多くの関連性を表現するのに適しています。

このモデルは、1960年代から1970年代にかけて、IBMの情報管理システムで主に使用されていました。しかし、運用面で非効率的なため、現在ではほとんど使用されていません。
ネットワークモデル
ネットワークモデルは、親となる複数の履歴を伴うリンクされた履歴間の多対多の関連を示すことにより、階層型モデルの形をとります。数学の集合論に基づき、関連する履歴の集合で構�成されるモデルです。集合はそれぞれ、1つのオーナーまたは親履歴と1つ以上のメンバーまたは子履歴から構成されます。ある履歴が複数の集合のメンバーや子となることもでき、複雑な関連を表現することが可能なモデルです。
データシステム言語協議会 (CODASYL) により正式に定義されて以降、1970年代に最も人気を博したモデルです。

オブジェクト指向データベースのモデル
このモデルでは、データベースを関連する機能やメソッドを持つオブジェクト、または再利用可能なソフトウェア要素の集合として定義します。オブジェクト指向データベースには以下の種類があります。
-
マルチメディアデータベース: 画像などのメディアを格納できるデータベースで、関係データベースには格納できないデータを含みます。
-
ハイパーテキストデータベース: 任意のオブジェクトを他の任意のオブジェクトにリンクできるデータベースです。異なる性質の多量のデータを整理するのに役立ちますが、数値解析にはあまり適していません。
-
ハイブリッドデータベースモデル: 表を組み込んだオブジェクト指向データベースモデルで、ポスト関係データベースモデルとして最も知名度があります。ただし、組み込む対象は表に限定されません。

オブジェクト関係データベースモデル
オブジェクト関係データベースモデルは、関係データベースの簡潔さとオブジェクト指向データベースモデルの高度な機能性を組み合わせたハイブリッドデータベースモデルです。設計者が使い慣れた表構造にオブジェクトを組み込める点が特長です。
このモデルでは、以下のような言語とコールインターフェイスが利用されます:
- SQL3: 標準SQLの第3版で、オブジェクト関係モデルで使用される拡張機能をサポートしています。
- ベンダー固有の言語: 各ベンダーが独自に提供するデータベース操作言語やインターフェイスです。
- ODBC: Open Database Connectivityの略で、さまざまなデータベースへのアクセスを標準化したAPIです。
- JDBC: Java Database Connectivityの略で、JavaプログラムからデータベースにアクセスするためのAPIです。
- 関係モデルで用いられる言語とインターフェイスの延長線上にある独自のコールインターフェイス: 特定の関係データベース管理システムが提供する独自のAPIやインターフェイスです。
これらの言語とインターフェイスを利用することで、オブジェクト関係モデルは柔軟性と拡張性を提供します。
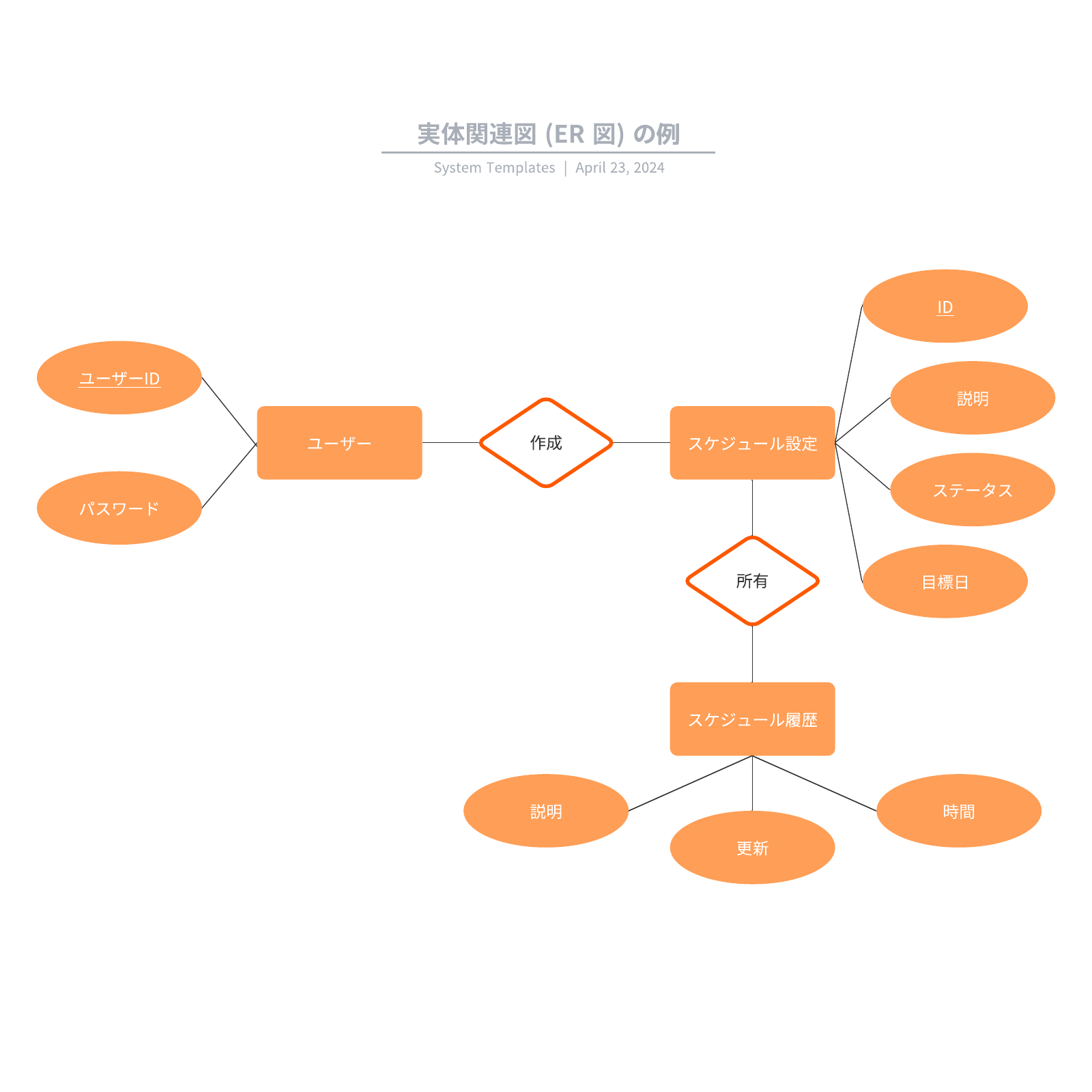
実体関連モデル(ER図)
実体関連モデルは、実世界の実体間の関連を示すデータベースモデルです。このモ�デルでは、ネットワークモデルと類似していますが、ネットワークモデルが物理的なデータベース構造に直接的に依存するのに対して、実体関連モデルはより概念的な設計を重視します。オブジェクト関係モデルと同様に、データベースの概念的な設計に広く用いられます。
ER図では、格納されたデータポイントに関連する人物、場所、または物事が「実体」として表現されます。それぞれの実体は、固有の属性を持つドメインを構成します。また、実体間の関連性も明示され、図示されることがあります。

人気のある実体関連図(ER図)の一種にはスタースキーマがあります。スタースキーマは、中央のファクト表(事実表)が多次元のデータベース表に接続される図式です。
その他のデータベースモデル
この他にもさまざまなデータベースモデルが存在します。
転置ファイルモデル
- 高速の全文検索を支援するために設計されたデータベースモデルで、データコンテンツがインデックス化されたキーとしてインデックステーブル内に格納されます。例として、Software AG のADABASデータベース管理システムで1970年代から使用されています。
フラットモデル
- 初期のデータベースモデルで、1つの表にデータを行と列で簡単に列挙するモデルです。小規模なデータセットには適していますが、データ�アクセスや操作が非効率な場合があります。
多次元モデル
- 関係モデルの拡張で、オンライン分析処理(OLAP)向けに設計されています。データベースは多次元のデータ構造を持ち、立方体のような形で表現されます。
半構造モデル
- データとスキーマの境界が不明瞭なモデルで、特定のウェブベースのデータソースや非構造化データを扱うのに適しています。
コンテキストモデル
- 他のデータベースモデルの要素を組み込むことができるモデルで、柔軟性が高く、複数のモデルの特性を組み合わせることができます。
連想モデル
- データを実体と関連に基づき分割し、それぞれに一意の識別子を割り当てます。このモデルでは、ソース、動詞、ターゲットという一意の識別子を持つリンクでデータを構造化します。
これらの他にも、以下のようなデータベースモデルが存在します:
- セマンティックモデル: 格納されたデータと実世界との関連を明確に示す情報を含むモデル。
- XMLデータベース: データを指定し、XML形式で格納することができるデータベース。
- 名前付きグラフ: ノードとエッジで構成されるデータを表現するグラフデータベース。
- トリプルストア: 主語、述語、目的語の3つ組(トリプル)でデータを格納するデータベース。
これらのモデルは、それぞれの特性や使用目的に応じて選択され、実世界のデータ管理や操作に活用されています。
非SQL データベースモデル
オブジェクトデータベースモデルの他にも、関係データベースモデルとは対照的な以下の非 SQL モデルがいくつか登場してきました。
グラフデータベースモデル
- ネットワークモデルよりもさらに柔軟で、ノードとエッジで構成されるデータを表現します。このモデルでは、複数のノード間に複数の関係を持たせることができ、非常に複雑な関連性を表現することができます。特に、ソーシャルネットワークや推薦システムなどの分野で有用です。
複数値モデル
- 属性が単一のデータポイントではなく、複数の値やデータリストを含めることができるモデルです。これにより、1つのエンティティが複数の値を持つことができ、関係モデルの単一の属性と比較して柔軟性が増します。例えば、1つの商品に対して複数のタグやカテゴリを持たせることができます。
ドキュメントモデル
- 文書や半構造化データの格納や管理を目的としたモデルです。JSONやXMLなどの形式でデータを格納し、階層的な構造を持つことができます。このモデルは、ウェブコンテンツ管理やコンテンツ配信ネットワーク (CDN)、さらにはユーザープロファイルやログデータなど、柔軟なデータ構造が必要な場面で広く使用されています。
これらのモデルは、それぞれの特性を活かして、異なるデータ管理の課題に対応するために設計されています。関係データベースモデル以外の非 SQL モデルは、特にデータの柔軟性や複雑な関係性の表現が求められる場面で役立ちます。
ウェブ上のデータベース
データベースの利用は、現代のさまざまな産業や活動に不可欠な要素となっています。ウェブサイトやオンラインサービス、オンラインショッピング、政治活動、産業の製造とサプライチェーン管理など、広範な分野でデータベースが活用されています。それぞれの業界では、データベースの設計や利用に関する独自の規範が設けられています。
データベース設計のベストプラクティス
適切に構築されたデータベース設計には、以下要素が考慮されております。
- 冗長データを排除し、ディスク容量を節約する。
- データの正確性と整合性を保つ。
- 便利な方法でのデータへのアクセスを可能にする。
効率的で有用なデータベース設計のためには、以下のステップを含め、ベストプラクティスの実行が肝要です。
- 要件の分析やデータベースの目的の定義
- 表形式でのデータの整理
- 主キーの指定と関連の分析
- 正規化による表の標準化
それでは、データベースの作り方の詳細を見ていきましょう。このガイドでは、(階層型、ネットワークやオブジェクトデータモデルではなく) SQL で記述されたエドガー・コッドの関係データベースモデルを主に取り扱っています。
データベースの作り方と基本的な構成要素
1. データベースの視覚的なレイアウ��トを決定する
まず、データベース内でどのようにデータを整理するかを考えます。データベースは、関連するデータを「表」という形でグループ化します。各表(テーブル)は、スプレッドシートのように「行(レコード)」と「列(フィールド)」で構成されます。
例:
「顧客」情報を格納する表を作成する場合:
| 名前 | 姓 | 年齢 | 郵便番号 |
|---|---|---|---|
| サチエ | タナカ | 43 | 563-0014 |
| ビル | ハンク | 32 | 192-0361 |
| ヒロコ | タケダ | 56 | 466-0843 |
このように、行(レコード)が個々のデータ(顧客ごとの情報)を表し、列(フィールド)はそのデータの属性(名前、年齢、住所など)を示します。

2. エンティティごとに表を作成する
データベースでは、情報をエンティティ(事象やオブジェクト)ごとに分けて表を作成します。例えば、顧客、製品、注文などのエンティティを表としてまとめ、関連するデータをそれぞれの表に保存します。
例:
- 顧客情報 → 顧客表
- 製品情報 → 製品表
- 注文情報 → 注文表
3. データ型の設定
データベースでは、各フィールドに対して適切なデータ型を設定します。これにより、データの一貫性と効率的な検索が可能になります。
よく使用されるデータ型:
- CHAR:固定長の文字列(例:郵便番号)
- VARCHAR:可変長の文字列(例:顧客の名前)
- TEXT:長文(例:製品の詳細説明)
- INT:整数(例:年齢、数量)
- FLOAT/DOUBLE:小数点を含む数値(例:価格)
- BLOB:バイナリデータ(例:画像ファイル)
また、オートナンバー(自動生成された番号)を使って、各レコードに一意のIDを割り当てることもよく行われます。
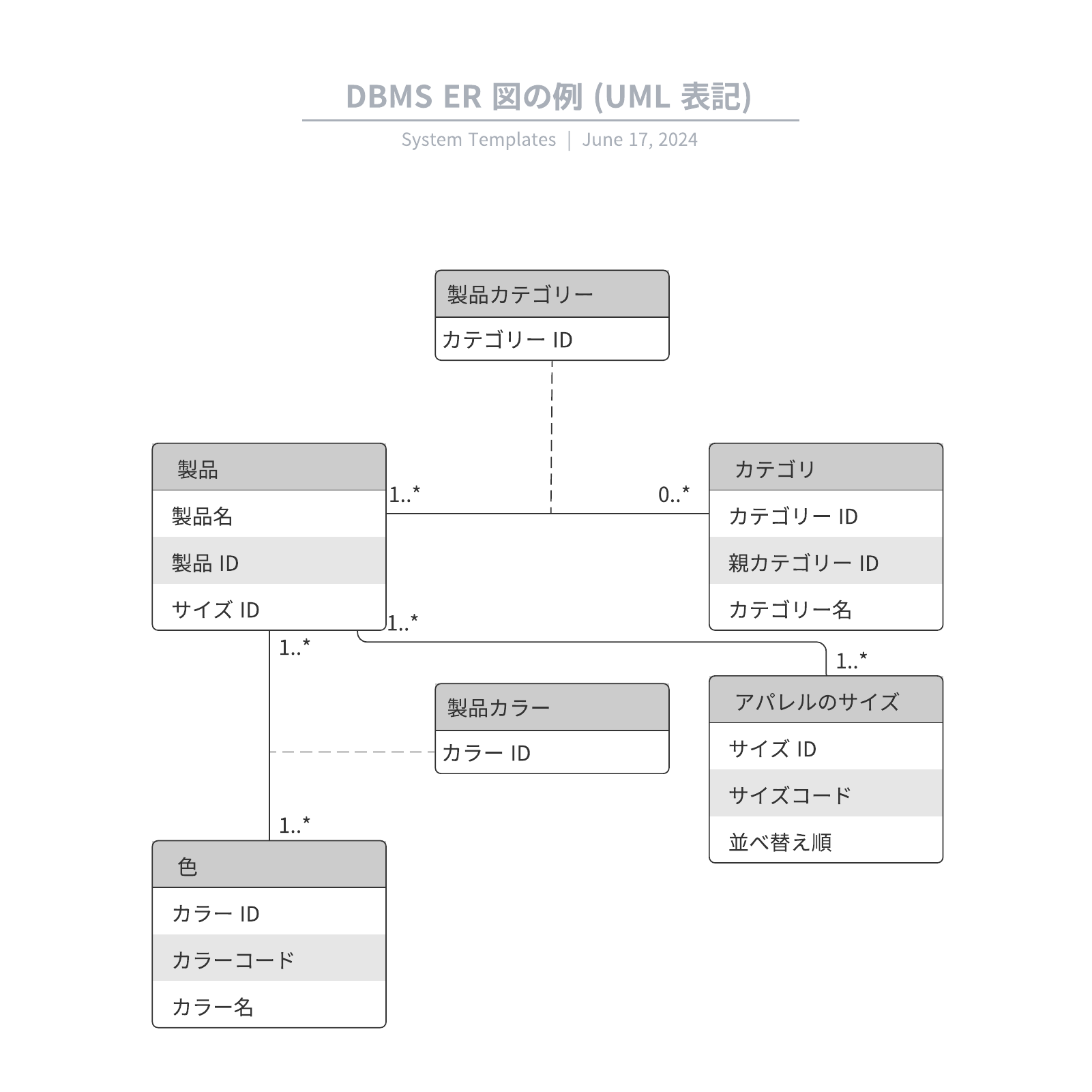
4. 実体関連図(ER図)を作成する
データベースの視覚的な設計には、実体関連図(ER図)を使用します。ER図では、各表をボックスで表し、それぞれの属性(列)はボックス内でリスト化されます。また、エンティティ間の関係を矢印や線で示すことができます。ER図を使うことで、データベース構造がより直感的に理解でき、設計ミスを防ぐことができます。
5. 主キー(PK)を決定する
各表には一意の識別子が必要です。この識別子を主キー(PK)と呼びます。主キーは、その表の各レコードを一意に識別するために使用されます。主キーとして選ばれるフィールドは、以下の条件を満たす必要があります。
- 一意である(重複しない)
- 変更されない(不変)
- 常に存在する(NULL値を許容しない)
例:
- 顧客表:顧客ID(主キー)
- 注文表:注文番号(主キー)
複数のフィールドを組み合わせて複合キーを作成することもできます。例えば、注文表で「顧客ID」と「注文日」を組み合わせて一意の識別子を作成する場合です。
6. 論理構造と物理構造を設計する
データベースの論理構造が決まったら、次はそれを物理的にどのように格納するかを設計します。使用するデータベース管理システム(DBMS)に適したデータ定義言語(DDL)を使用して、実際にテーブルを作成します。また、データベースのサイズやパフォーマンスに応じて、必要なストレージ容量を見積もることも重要です。
注意点:
- パフォーマンス最適化: データベースの検索や更新速度を向上させるために、インデックスを追加したり、データの正規化を行うことがあります。
- データサイズの見積もり: ストレージ容量を適切に見積もることで、システムの動作が遅くなるのを防ぎます。
データベース設計における関連の分析
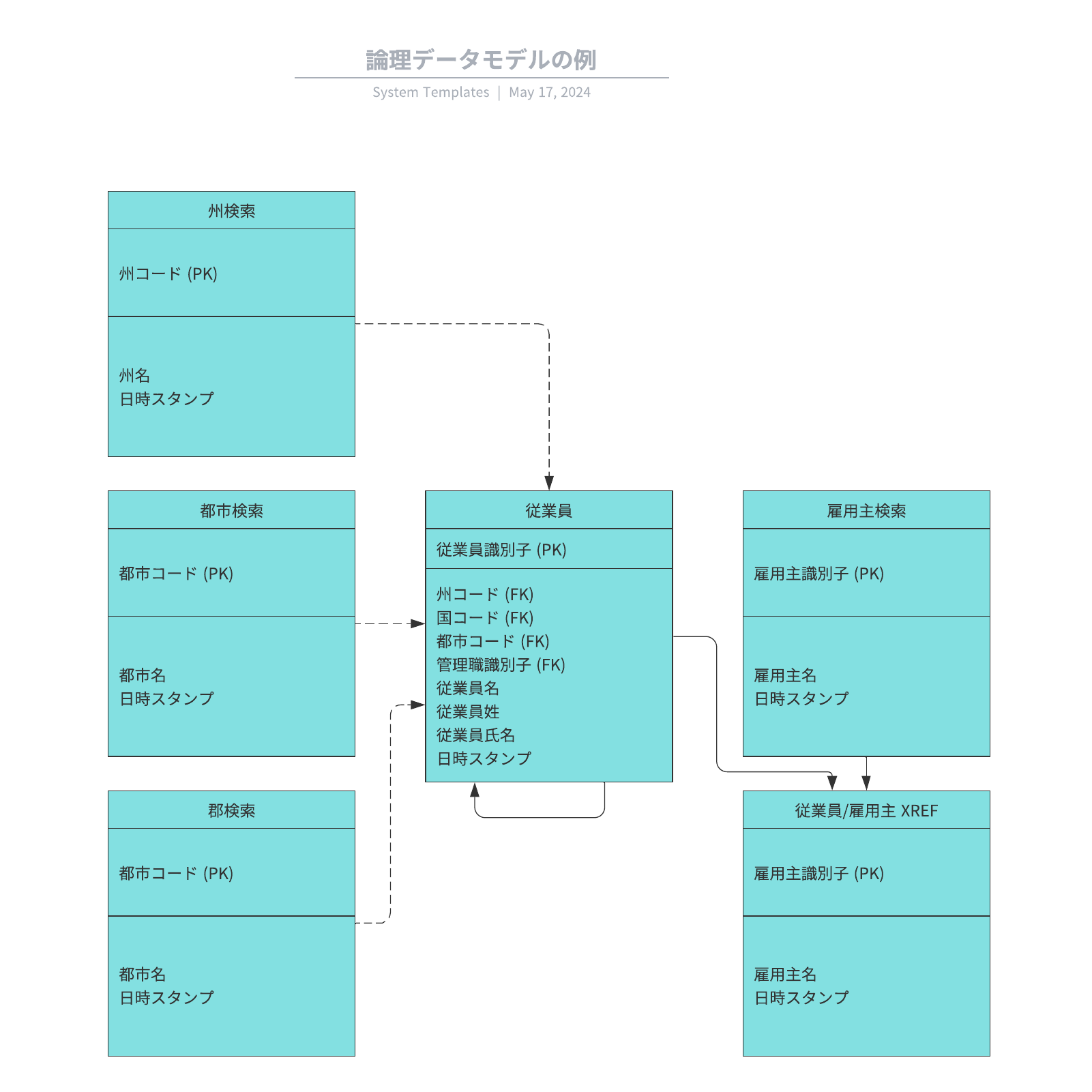
データベース設計の段階では、データを表形式に整理し、異なる表(テーブル)間の関連を明確にすることが重要です。これにより、データが適切に分割されているか、効率的に管理されているかを確認できます。この段階で「濃度」を分析することが必要です。
濃度の分析
「濃度」とは、異なる表間で共有される情報の量を�指します。具体的には、関連する2つのテーブルでやり取りされるデータの頻度や量を測ります。濃度を特定することで、データが適切に分割されているか、無駄な重複がないかをチェックできます。
例えば、顧客情報と注文情報をそれぞれ別のテーブルに分けた場合、顧客IDと注文IDがどのように関連しているかを見ます。この「関連」が適切に設計されていれば、データベースは効率的に動作します。
実体間の関連の種類
実体(テーブル)間の関連には、以下の3つの基本的なタイプがあります。これらを理解し、適切なリレーションシップを設計することがデータベースの効率を高めます。
1. 1対1の関連(One-to-One)
1対1の関連は、1つのテーブルのレコードが別のテーブルの1つのレコードにだけ関連する場合に使います。たとえば、ある顧客に対して1つの顧客詳細情報がある場合です。
- ER図では、1対1の関連を示すために、関連の両端に「ダッシュ」をつけた線で表現します。
- 1対1の関連は通常、2つのテーブルを1つに統合しても問題ない場合が多いです。ただし、特別な理由がある場合、別々のテーブルとして保持することもあります。例えば、「説明」のような省略可能なフィールドを分けて管理し、データベースのパフォーマンスを向上させる場合があります。

2. 1対多の関連(One-to-Many�)
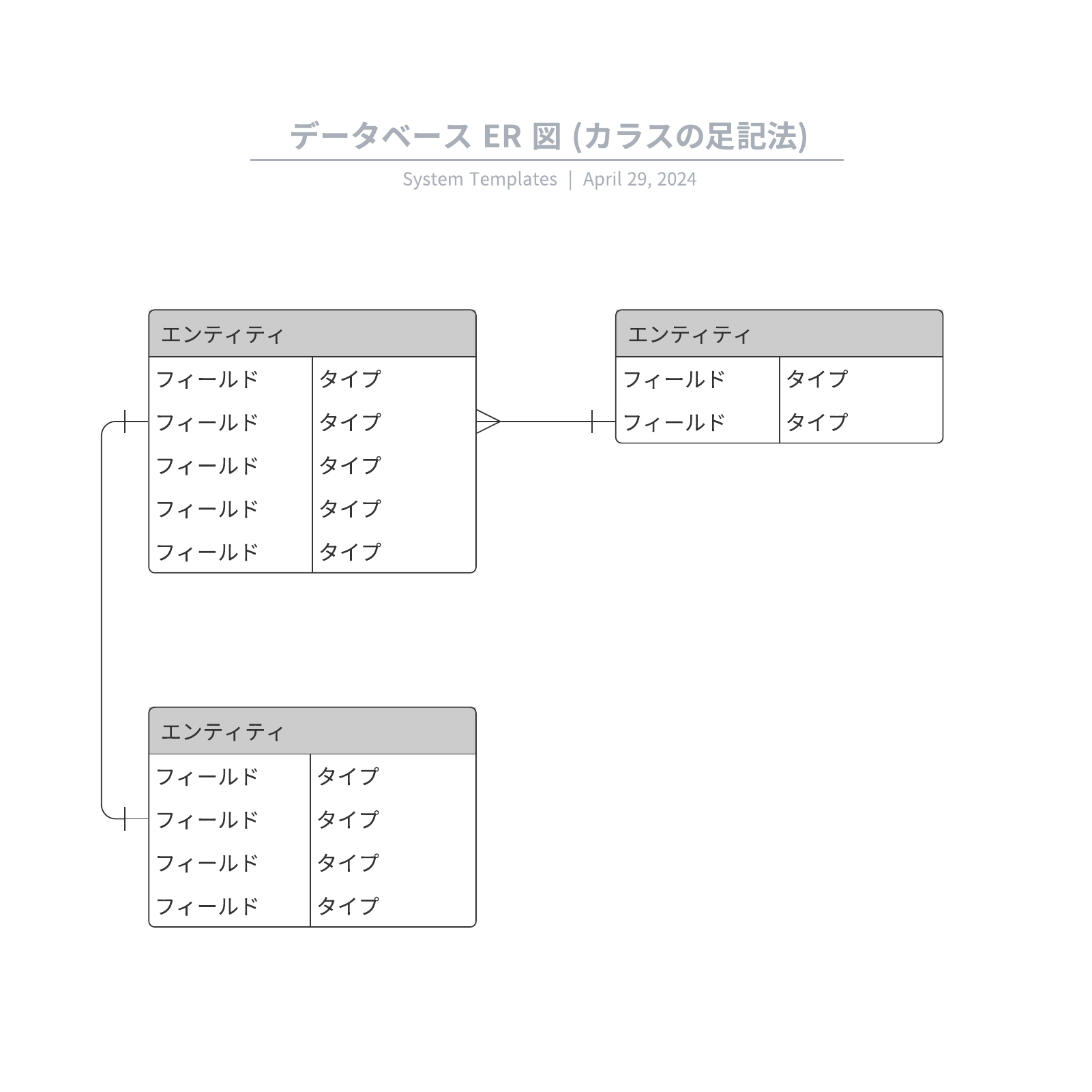
1対多の関連は、1つのテーブルのレコードが別のテーブルの複数のレコードに関連する場合です。たとえば、1人の顧客が複数の注文を行う場合がこれに該当します。
- ER図では、「カラスの足記法」で示されます。
- 実装方法:1対多の関連を実現するには、1側のテーブルの主キー(Primary Key)を、もう1つのテーブルに追加して「外部キー(Foreign Key)」として使用します。これにより、親テーブル(1側)と子テーブル(多側)を関連付けます。

3. 多対多の関連(Many-to-Many)
多対多の関連は、2つのテーブルのレコードが互いに複数回関連する場合です。例えば、学生と授業の関係では、1人の学生が複数の授業を受け、1つの授業には複数の学生が参加します。
- ER図では、矢印付きの線で示されます。

- 直接多対多の関連はデータベースで表現できないため、2つの1対多の関連に分けてリンクテーブル(中間テーブル)を作成します。例えば、「学生」テーブルと「授業」テーブルの間に、「学生授業」テーブルを作成して関連を表現します。このリンクテーブルには、学生IDと授業ID��が含まれ、これらが1対多の関連で繋がります。

その他の関連の種類
必須か否かの判定
関連を設計する際には、ある実体の存在がもう一方の実体の存在に必須かどうかを確認することも重要です。例えば、ある国の国連代表が存在するには、その国が存在する必要がありますが、逆に国が存在すれば必ず国連代表が存在するわけではありません。この場合、必須でない側には線上に丸をつけることで表現します。

再帰関連(Recursive Relationship)
時には、テーブルがその自分自身を参照することがあります。例えば、従業員テーブルに「マネージャー」属性があり、従業員が他の従業員を管理するような場合です。これは再帰関連と呼ばれます。
冗長関連
複数の方法で同じ情報を関連付けることがある場合、その関連が冗長である可能性があります。冗長な関連を取り除くことで、データベースがシンプルで効率的になります。例えば、学生と教師が直接関連し、さらに授業を通じて間接的にも関連している場合、学生と教師の直接的な関連は削除できます。授業を介してのみ教�師と学生が関連していれば、それが最適な設計です。
このように、データベース設計では、関連の種類や濃度を正しく分析し、データが効率的に保存されるようにすることが重要です。各関連を適切に理解し、実装することで、データベースのパフォーマンスと一貫性が保たれます。
データベースの正規化の手順
データベースの正規化
データベース設計が進んだ段階では、データが適切に分割され、冗長性が排除されていることを確認するために「正規化」を行います。正規化は、データの整合性を保ち、データベースの効率を高めるために非常に重要です。
ただし、すべてのデータベースが正規化を完全に適用すべきではありません。例えば、OLTP(オンライントランザクション処理)データベースでは、ユーザーが頻繁にデータの作成、更新、削除を行うため、正規化が推奨されます。一方で、OLAP(オンライン分析処理)データベースでは、分析速度を重視するため、ある程度の非正規化が有利となることがあります。
正規化は、以下のような段階(正規形)で進められます。各正規形には、データの分割や依存関係に関する特定のルールがあります。
第1正規形(1NF)
第1正規形(1NF)では、テーブルの各セルに1つの値のみが格納されるべきだというルールがあります。つまり、複数の値やリストを1つのセルに格納することは許されません。
例:
下�記のテーブルは第1正規形に違反しています。色の列に複数の値(茶、黄、赤、緑など)が含まれています。
| 製品ID | 色 | 価格 |
|---|---|---|
| 1 | 茶、黄 | $15 |
| 2 | 赤、緑 | $13 |
| 3 | 青、オレンジ | $11 |
これを第1正規形に適合させるには、色を別々の行に分ける必要があります。例えば、「製品ID 1」に関して、茶と黄をそれぞれ別の行として記録します。
| 製品ID | 色 | 価格 |
|---|---|---|
| 1 | 茶 | $15 |
| 1 | 黄 | $15 |
| 2 | 赤 | $13 |
| 2 | 緑 | $13 |
| 3 | 青 | $11 |
| 3 | オレンジ | $11 |
このように、各セルに1つの値のみを持たせることで、データが整理され、より効率的に管理できます。
第2正規形(2NF)
第2正規形(2NF)では、テーブルの各属性が主キー全体に完全に依存している必要があります。つまり、主キーが複数のフィールドから構成される場合、各属性はその主キー全体に依存しなければなりません。
例:
次のテーブルでは、製品名が製品IDに依存していますが、注文番号には依存していません。このため、このテーブルは第2正規形に違反しています。
| 注文番号 | 製品ID | 製品名 |
|---|---|---|
| 1001 | 1 | テレビ |
| 1002 | 2 | 冷蔵庫 |
| 1003 | 1 | テレビ |
このテーブルでは、製品名は製品IDに依存しており、注文番号には依存していません。したがって、製品名を製品IDに基づく別のテーブルに分割し、冗長性を排除する必要があります。
第3正規形(3NF)
第3正規形(3NF)では、すべての非キー列が他の非キー列に依存しないようにする必要があります。具体的には、ある列の値が変更された場合に、他の列の値が影響を受けないようにします。
例:
次のテーブルでは、税金が価格に依存しています。価格が変更されると税金も変更されるため、このような表は第3正規形に違反しています。
| 注文番号 | 価格 | 税金 |
|---|---|---|
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $0.69 |
| 14327 | $24.15 | $1.21 |
この場合、税金を計算するために価格を使うので、税金は価格に依存しています。この依存関係を解消するために、税金は計算に基づくフィールドとして定義すべきです。例えば、税金は別のテーブルに格納し、価格に変更があった場合に動的に再計算する方が望ましいです。
正規化の目的と限界
正規化の目的は、データの冗長性を排除し、データの整合性を保つことです。しかし、過度に正規化すると、データベースのパフォーマンスが低下することがあります。特に、複雑な結合が必要な場合、読み取り速度が遅くなることがあります��。
そのため、データベースの設計には、データの性質や利用目的を考慮して、適切な正規化レベルを選ぶことが重要です。特にOLAP(オンライン分析処理)のようなデータを集計・分析する用途では、データベースを非正規化して、計算速度を重視することが適している場合もあります。
多次元データ

データの整合性ルール
データベースを適切に構成し、ルールに従ってデータを検証することは非常に重要です。Microsoft Accessを含む多くのデータベース管理システムには、こうしたルールを自動的に適用する機能が備わっています。
-
実体整合性ルール: 主キーをNULLにすることは許されません。主キーが複数の列で構成される場合、それぞれの列もNULLにすることはできません。このルールに違反すると、履歴を一意に識別することができなくなる可能性があります。
-
参照整合性ルール: 外部キーは、参照先の表内の主キーと一致しなければなりません。主キーに対して変更や削除を行った場合、これらの変更内容をデータベース全体のすべての参照元に反映させる必要があります。
-
ビジネスロジック整合性ルール: データが特定のビジネスルールや論理パラメータに従うことを確保します。例えば、予約時間は通常営業時間内に収まる必要があります。
これらの整合性ルールを厳密に遵守することで、データベースの信頼性や効率性を高め、データの品質を保つことができます。データベース管理システムが提供する自動適用機能を活用することで、エラーや不整合を未然に防ぐことができます。
インデックスとビューの追加
インデックスは、本質的には並べ替えられた1つまたは複数の列のコピーで、昇順または降順で値が並ぶものを指します。インデックスを追加することで、ユーザーはデータをより効率的に取得できるようになります。システムは、クエリを再度データを並べ替えることなく、インデックスで指定された順序でデータにアクセスすることができます。
しかし、インデックスを使用することでデータ取得の速度が向上する一方で、履歴に変更が加えられるたびにインデックスの再構築が必要となります。そのため、データの挿入、更新、削除の速度が低下する可能性があります。
ビューは、データベースに保存されたクエリを指します。複数の表からのデータの結合や特定の表の一部の表示を行う際に便利です。ビューを使用することで、データの複雑な結合や必要な部分の抽出を容易に行うことができます。
拡張プロパティ
基本的なレイアウトが完成したら、指示テキスト、入力マスク、特定のスキーマ、ビューや列に適用する形式設定ルールなどの拡張プロパティを使ってデータベースを調整します。これらのルールはデータベース自体に格納されるため、そのデータにアクセスする複数のプログラム全体でデータの整合性を確保できるという利点があります。
SQL と UML
オブジェクト指向言語で作成された複雑なシステムを視覚的に表現するためのもう一つの方法が統一モデリング言語 (UML) です。このガイドで取り上げた概念のいくつかは、UML においては別の名前で表現されます。例えば、実体は UML ではクラスと呼ばれます。
UML はかつてほどは使われなくなり、現在では、学術用途やソフトウェア設計者とクライアントの間のコミュニケーション手段として主に使われています。
4分でわかる Lucidchart データベース ツールの基本的な使い方
- さっそく最初の図を作成してみましょう。文書をインポートするか、テンプレートを使用するか、空白のキャンバスで最初から作図を始めます。
- 図の図形や記号、線を追加します。
- [機能を検索] を使えば、図内の必要な情報を検索できます。
- 図をチームと共有して、共同作業からフィードバックを得ることができます。
*このビデオは英語のみとなります。予めご了承いただけますようお願いいたします。