Qu'est-ce qu'un schéma de base de données ?
Un schéma de base de données représente la configuration logique de tout ou partie d'une base de données relationnelle. Il peut se présenter à la fois sous la forme d'une représentation visuelle et d'un ensemble de formules, appelées « contraintes d'intégrité », qui régissent une base de données. Ces formules sont exprimées dans un langage de définition des données, tel que SQL. Dans le cadre d'un dictionnaire de données, un schéma de base de données indique comment les entités qui composent la base de données se rapportent les unes aux autres, notamment les tables, les vues et les procédures stockées.

En règle générale, un concepteur de base de données crée un schéma de base de données pour aider les programmeurs dont le logiciel va interagir avec la base de données. Le processus de création d'un schéma de base de données se traduit par la modélisation des données. Dans le cadre de l'approche à trois schémas de conception de bases de données, cette étape suivrait la création d'un schéma conceptuel. Les schémas conceptuels se concentrent sur les besoins en informations d'une organisation plutôt que sur la structure d'une base de données.
Il existe deux principaux types de schémas de base de données :
- Un schéma de base de données logique transmet les contraintes logiques applicables aux données stockées. Il peut définir des contraintes d'intégrité, des vues et des tables.
- Un schéma de base de données physique expose la manière dont les données sont stockées physiquement sur un système de stockage en termes de fichiers et d'index.
Au niveau le plus élémentaire, un schéma de base de données indique quelles tables ou relations constituent la base de données, ainsi que les champs inclus dans chaque table. Ainsi, les termes diagramme schématique et diagramme entité-association sont souvent interchangeables.
Maîtrisez les bases de Lucidchart en 5 minutes
- Créez votre premier diagramme à partir d’un modèle ou d’une zone de travail vierge ou importez un document.
- Ajoutez du texte, des formes et des connexions pour personnaliser votre diagramme.
- Découvrez comment ajuster le style et la mise en forme.
- Trouvez ce dont vous avez besoin grâce à la recherche de fonctionnalités.
- Partagez votre diagramme avec votre équipe pour commencer à collaborer.
Schéma dans un système de base de données Oracle
Dans le système de base de données d'Oracle, le terme schéma de base de données, également connu sous le nom de « schéma SQL », a une signification différente. Dans ce cadre, une base de données peut comporter plusieurs schémas. Chacun contient tous les objets créés par un utilisateur spécifique de base de données. Ces objets peuvent inclure des tables, des vues et des synonymes, entre autres. Certains objets ne peuvent pas être inclus dans un schéma : utilisateurs, contextes, rôles et objets d'annuaire.

L'accès à chaque schéma est octroyé au cas par cas, et la propriété est cessible. Chaque objet étant associé à un schéma particulier, qui sert en quelque sorte d'espace de noms, il est utile de donner quelques synonymes, ce qui permet à d'autres utilisateurs d'accéder à cet objet sans se reporter d'abord au schéma auquel il appartient.
Ces schémas n'indiquent pas nécessairement la manière dont les fichiers de données sont stockés physiquement. Au lieu de cela, les objets de schéma sont stockés logiquement dans un tablespace. L'administrateur de la base de données peut spécifier la quantité d'espace à attribuer à un objet particulier dans un fichier de données.
Enfin, les schémas et les tablespaces ne correspondent pas nécessairement à la perfection : on peut trouver des objets d'un schéma dans plusieurs tablespaces, et un tablespace peut inclure des objets issus de plusieurs schémas.
Instance de base de données ou schéma de base de données ?
Ces termes, bien que connexes, ne signifient pas la même chose. Le schéma d'une base de données est l'ébauche d'une base de données planifiée. Il ne contient pas réellement de données.
En revanche, une instance de base de données est un instantané d'une base de données telle qu'elle existait à un moment donné. Ainsi, les instances de base de données peuvent changer au fil du temps, alors qu'un schéma de base de données est généralement statique, car il est difficile de changer la structure d'une base de données une fois qu'elle est opérationnelle.
Les schémas de base de données et les instances de base de données peuvent influer les uns sur les autres via un système de gestion de base de données (SGBD). Le SGBD veille à ce que chaque instance de base de données respecte les contraintes imposées par les concepteurs de bases de données dans le schéma de base de données.
Exigences d'intégration au schéma
Il peut être utile d'intégrer plusieurs sources dans un schéma. Assurez-vous que les exigences suivantes soient remplies pour une transition en douceur :
Préservation des chevauchements
Tout chevauchement d'un élément dans les schémas que vous intégrez doit se retrouver dans une table de schéma de base de données.
Préservation des chevauchements étendus
Les éléments qui n'apparaissent que dans une seule source, mais qui sont associés à des éléments qui se chevauchent, doivent être copiés dans le schéma de base de données résultant.
Normalisation
Les relations et les entités indépendantes ne doivent pas être regroupées dans une même table dans le schéma de base de données.
Minimalité
Dans l'idéal, aucun des éléments de l'une des sources ne doit être perdu.
Types de schémas de base de données
Certains modèles ont émergé au fil de la conception de schémas de base de données.
Le schéma en étoile, largement utilisé, est aussi le plus simple. Dans ce dernier, une ou plusieurs tables de faits sont liées à un certain nombre de tables de dimensions. Ce type de schéma est préférable pour traiter des requêtes simples.
On utilise aussi un schéma lié, le schéma en flocon, pour représenter une base de données multidimensionnelle. Néanmoins, dans ce modèle, les dimensions sont normalisées en lots de tables distinctes, créant l'effet étendu d'une structure en flocon de neige.
Comment concevoir une structure de base de données ?
Processus de conception d'une base de données
Une base de données bien structurée :
- libère de l'espace disque en éliminant les données redondantes ;
- préserve l'exactitude et l'intégrité des données ;
- permet d'accéder efficacement aux données.
Pour concevoir une base de données efficace et utile, vous devez suivre le bon processus, qui comprend les phases suivantes :
- Analyse des besoins, c'est-à-dire l'identification de l'objet de votre base de données
- Organisation des données en tables
- Spécification des clés primaires et analyse des relations
- Normalisation des tables
Regardons chaque étape d'un peu plus près. Notez que ce guide est basé sur le modèle SQL de base de données relationnelle d'Edgar Codd (et non pas sur les modèles de données hiérarchiques, de réseau ou d'objets). Pour en savoir plus sur les modèles de bases de données, consultez cette rubrique de l'article.
Analyse des besoins : identification de l'objet de la base de données
La compréhension de l'objet de votre base de données guidera vos choix tout au long du processus de conception. Assurez-vous de réfléchir à votre base de données sous tous les angles. Par exemple, si vous décidiez de créer une base de données pour une bibliothèque municipale, il vous faudrait tenir compte des possibilités d'accès aux données pour la clientèle comme pour les bibliothécaires.
Voici quelques moyens de recueillir des informations avant de créer la base de données :
- Interroger les personnes qui vont l'utiliser
- Analyser des formulaires d'entreprise, tels que des factures, des feuilles de présence, des enquêtes
- Passer en revue tout système de données existant (en incluant tous les fichiers physiques et numériques)
Commencez par rassembler toutes les données existantes qui seront intégrées à la base de données. Ensuite, faites une liste des types de données que vous souhaitez conserver et des entités – ou des personnes, objets, lieux et événements – que ces données décrivent, comme suit :
Clients
- Nom
- Adresse
- Ville, État, code postal
- Adresse e-mail
Produits
- Nom
- Montant
- Quantité en stock
- Quantité commandée
Commandes
- Numéro de commande
- Représentant commercial
- Date
- Produit(s)
- QUANTITÉ
- Montant
- Total
Plus tard, ces informations feront partie du dictionnaire des données, qui détermine les tables et les champs présents au sein de la base de données. Assurez-vous d'avoir décomposé les informations jusqu'aux fragments les plus petits possible. Par exemple, séparez l'adresse postale de la mention du pays pour que vous puissiez par la suite filtrer les personnes en fonction de leur pays de résidence. Évitez également de placer le même élément d'information dans plus d'une table, pour ne pas complexifier inutilement la structure de la base de données.
Une fois que vous savez quels types de données comprendra votre base de données, d'où proviendront les données et comment elles seront utilisées, vous êtes prêt à commencer à concevoir votre base de données à proprement parler.
Structure de la base de données : composantes d'une base de données
L'étape suivante consiste à créer une représentation visuelle de votre base de données. Pour ce faire, vous devez comprendre exactement comment les bases de données relationnelles sont structurées.
Dans une base de données, les données apparentées sont regroupées dans des tables, chacune étant composée de lignes (également appelées tuples) et de colonnes, comme une feuille de calcul.
Pour convertir vos listes de données en tables, commencez par créer une table pour chaque type d'entité, comme les produits, les ventes, les clients et les commandes. Voici un exemple :
Chaque ligne d'une table est appelée enregistrement. Les enregistrements contiennent des données sur un objet ou une personne, par exemple un client donné. En revanche, les colonnes (également connues sous le nom de champs ou d'attributs) contiennent un seul type d'information qui apparaît dans chaque enregistrement, par exemple les adresses de tous les clients figurant dans la table.
| Prénom | Nom | Âge | Code postal |
|---|---|---|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Pour faire en sorte que les données restent cohérentes d'un enregistrement à l'autre, assignez le bon type de donnée à chaque colonne. Les types de données les plus courants sont :
- CHAR : texte d'une longueur spécifique
- VARCHAR : texte de longueur variable
- TEXT : grandes quantités de texte
- INT : nombre entier positif ou négatif
- FLOAT, DOUBLE : types de variables permettant aussi stocker des nombres à virgule flottante
- BLOB : données binaires
Certains systèmes de gestion de base de données proposent également le type de données AutoNumber, qui génère automatiquement un numéro unique pour chaque ligne.
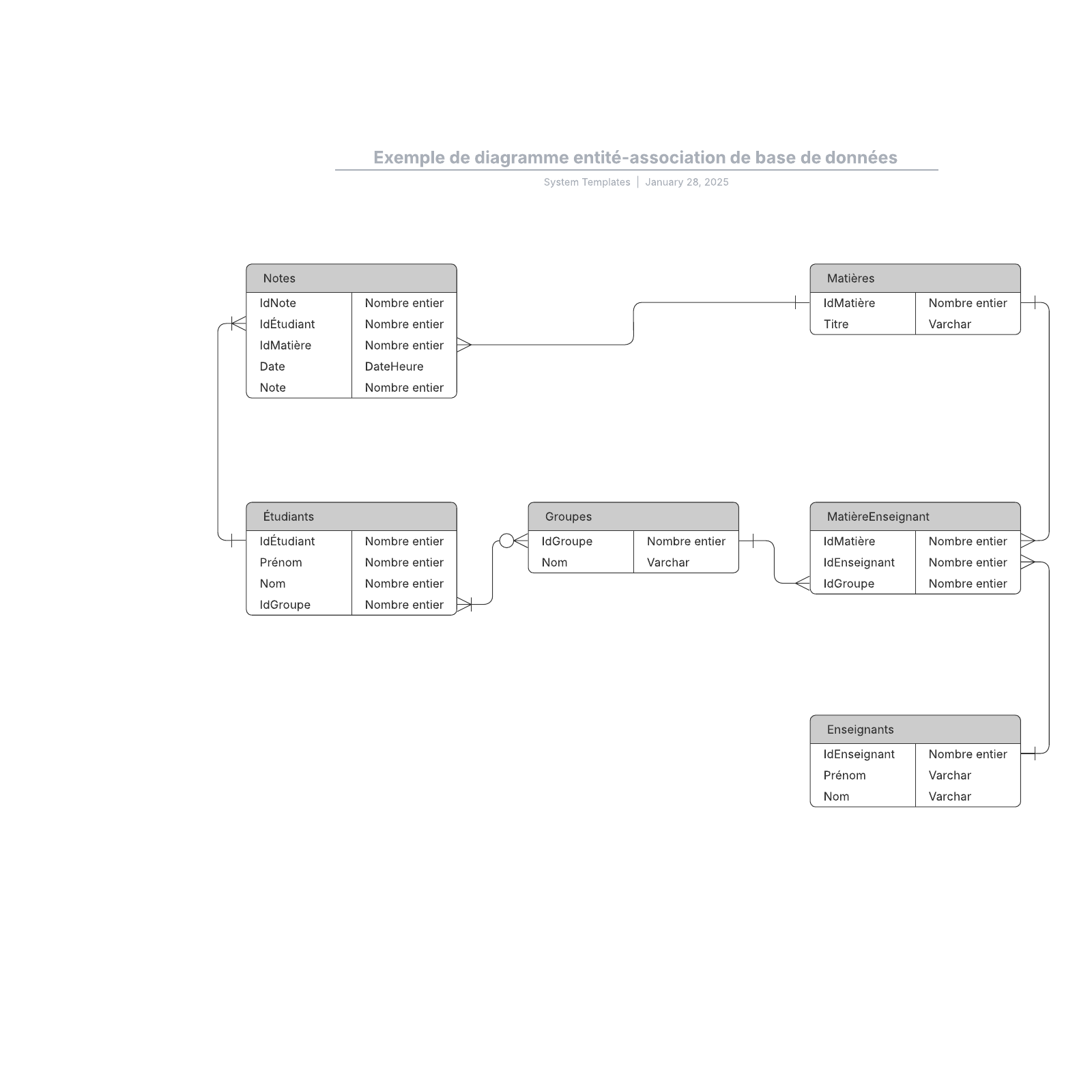
Pour créer une vue d'ensemble de la base de données, appelée diagramme entité-association, n'incluez pas les tables. En effet, chaque table devient une boîte dans le diagramme. Le titre de chaque boîte doit indiquer ce que les données de cette table décrivent, tandis que les attributs sont listés en dessous, comme illustré ci-après :

Enfin, vous devez décider quel(s) attribut(s) seront utilisés comme clé primaire pour chaque table, s'il y en a une. Une clé primaire est un identifiant unique pour une entité donnée, ce qui signifie que vous pourriez par exemple identifier un client en ne disposant que de cette information.
Les attributs choisis comme clés primaires doivent être uniques, immuables et toujours présents (jamais NULL ou vides). C'est pour cette raison que les numéros de commande et les noms d'utilisateurs font de bonnes clés primaires, contrairement aux numéros de téléphone ou aux adresses. Vous pouvez aussi associer plusieurs champs dans une clé primaire (ce que l'on appelle une clé composite).
Lorsque viendra le moment de créer la véritable base de données, vous intégrerez à la fois la structure de données logiques et la structure de données physiques dans le langage de définition des données pris en charge par votre système de gestion de base de données. À ce stade, vous devrez également estimer la taille de la base de données pour vous assurer de disposer du niveau de performance et de l'espace de stockage nécessaires.
Création de relations entre les entités
Vos données étant maintenant converties en tables, vous êtes prêt à analyser les relations entre ces tables. La cardinalité fait référence à la quantité d'éléments qui interagissent entre deux tables connexes. L'identification de la cardinalité permet de vous assurer que vous avez réparti les données dans des tables de la façon la plus efficace possible.
Chaque entité peut avoir une relation avec toutes les autres, mais ces relations appartiennent généralement à l'une des trois catégories suivantes :
Relations un-à-un
Lorsqu'il n'existe qu'une seule instance de l'entité A pour chaque instance de l'entité B, on dit qu'elles ont une relation biunivoque ou un-à-un (souvent écrite 1:1). Vous pouvez représenter ce type de relation dans un diagramme entité-association par une ligne se terminant par un trait à chaque extrémité :

Sauf si vous avez une bonne raison de ne pas le faire, une relation 1:1 indique généralement qu'il est préférable de combiner les données des deux tables en une seule table.
Cependant, la création de tables disposant d'une relation 1:1 peut se justifier dans certaines circonstances. Si vous disposez d'un champ facultatif, comme « description » qui est vide dans la plupart des enregistrements, vous pouvez déplacer toutes les descriptions dans leur propre table, ce qui supprime l'espace vide et améliore les performances de la base de données.
Pour faire en sorte que les données correspondent bien, il vous faudra alors inclure au moins une colonne identique dans chaque table, très probablement la clé primaire.
Relations un-à-plusieurs
Ces relations se produisent lorsqu'un enregistrement d'une table est associé à plusieurs enregistrements d'une autre table. Par exemple, un client donné peut avoir passé plusieurs commandes, ou un usager peut avoir emprunté de nombreux livres simultanément à la bibliothèque. Les relations un-à-plusieurs (1:M) sont représentées par ce que l'on appelle une notation en « patte de corbeau », comme dans l'exemple ci-dessous :

Pour instaurer une relation 1:M lorsque vous mettez en place une base de données, il vous suffit d'ajouter la clé primaire du côté « un » de la relation en tant qu'attribut dans l'autre table. Lorsqu'une clé primaire est listée dans une autre table de cette façon, on l'appelle clé étrangère. La table du côté « un » de la relation est considérée comme un parent de la table enfant de l'autre côté.
Relations plusieurs-à-plusieurs
Lorsque plusieurs entités d'une table peuvent être associées à plusieurs entités d'une autre table, on dit qu'elles ont une relation plusieurs-à-plusieurs (M:N). Cette situation pourrait se produire dans le contexte d'une base associée à un système scolaire, car un étudiant peut assister à plusieurs cours et un cours peut compter plusieurs étudiants.
Dans un diagramme entité-association, ces relations sont représentées à l'aide des lignes suivantes :

Malheureusement, il n'est pas directement possible de mettre en place ce genre de relation dans une base de données. Au lieu de cela, vous devez la diviser en deux relations un-à-plusieurs.
Pour ce faire, créez une entité entre ces deux tables. Si la relation M:N existe entre ventes et produits, vous pouvez par exemple appeler cette nouvelle entité « produits_vendus », car elle montrera le contenu de chaque vente. Les tables ventes et produits auront toutes deux une relation 1:M avec produits_vendus. Ce type d'entité intermédiaire est appelée table de lien, entité associative ou table de jonction selon les modèles.
Chaque enregistrement de la table d'association correspondrait à deux des entités des tables voisines (et pourrait potentiellement inclure des informations supplémentaires). Par exemple, une table d'association entre des élèves et des cours pourrait ressembler à ceci :

Obligatoire ou non ?
Une autre façon d'analyser les relations consiste à déterminer quel côté de la relation doit exister pour que l'autre existe. Le côté facultatif peut être marqué d'un cercle sur la ligne où se trouverait le tiret. Par exemple, un pays doit exister pour être représenté à l'ONU, mais l'inverse n'est pas vrai :
Deux entités peuvent dépendre l'une de l'autre (l'une ne pourrait exister sans l'autre).
Relations récursives
Parfois, une table pointe vers elle-même. Ce serait le cas pour une table contenant des employés et disposant d'un attribut « responsable » faisant référence à une autre personne dans la même table. Il s'agit alors d'une relation récursive.
Relations redondantes
Une relation redondante est une relation qui est exprimée plus d'une fois. En règle générale, vous pouvez supprimer l'une des relations sans perdre aucune information importante. Par exemple, si une entité « étudiants » a une relation directe avec une autre appelée « enseignants », mais a aussi une relation avec les enseignants de façon indirecte par le biais des « cours », supprimez la relation entre les « étudiants » et les « enseignants ». Il est préférable de supprimer cette relation, car la seule façon dont les étudiants sont « attribués » aux enseignants est par le biais des cours.
Normalisation des bases de données
Une fois que vous disposez d'un design préliminaire pour votre base de données, vous pouvez appliquer les règles de normalisation pour vous assurer que les tables sont structurées correctement. Ces règles sont en quelque sorte les normes appliquées dans le domaine.
Cela dit, toutes les bases de données ne se prêtent pas à la normalisation. En général, les bases de données OLTP (traitement transactionnel en ligne), dans lesquelles les utilisateurs travaillent sur la création, la lecture, la mise à jour et la suppression d'enregistrements, doivent être normalisées.
Les bases de données OLAP (traitement analytique en ligne), qui favorisent l'analyse et les rapports, peuvent être plus efficaces avec un certain degré de dénormalisation, étant donné que l'accent est mis sur la vitesse de calcul. Elles comprennent des applications d'aide à la décision dans lesquelles les données doivent être analysées rapidement, mais pas modifiées.
Chaque forme, ou niveau de normalisation, comprend les règles associées aux formes inférieures.
Première forme normaleLa première forme normale (en abrégé 1FN ou 1NF en anglais) précise que chaque cellule de la table ne peut avoir qu'une seule valeur, et jamais une liste de valeurs. Une table comme celle qui suit n'est donc pas conforme :
| IDproduit | Couleur | Montant |
|---|---|---|
| 1 | marron, jaune | 15 $ |
| 2 | rouge, vert | 13 $ |
| 3 | bleu, orange | 11 $ |
Vous pourriez être tenté de contourner ce problème en divisant les données en colonnes supplémentaires, mais cette solution est elle aussi contraire aux règles : une table comportant des groupes d'attributs répétés ou proches les uns des autres n'est pas conforme à la première forme normale. La table ci-dessous, par exemple, n'est pas conforme :
Répartissez plutôt les données dans plusieurs tables ou enregistrements jusqu'à ce que chaque cellule ne contienne qu'une valeur et qu'il n'y ait plus de colonnes superflues. On dit alors que les données sont atomiques, c'est-à-dire qu'elles ont été décomposées jusqu'à la plus petite taille utile possible. Pour la table ci-dessus, vous pourriez créer une table supplémentaire intitulée « Détails des ventes » qui ferait correspondre chaque produit avec les ventes. « Ventes » aurait alors une relation 1:M avec « Détails des ventes ».
Deuxième forme normaleLa deuxième forme normale (2FN) exige que chacun des attributs dépende entièrement de la clé primaire. Cela signifie que chaque attribut doit dépendre directement de la clé primaire, et non indirectement par l'intermédiaire d'un autre attribut.
Par exemple, un attribut « âge » qui dépend de « date de naissance », qui dépend à son tour de l'« identifiant étudiant » est considéré comme ayant une dépendance fonctionnelle partielle. Une table contenant ces attributs ne serait pas conforme à la deuxième forme normale.
En outre, une table ayant une clé primaire composée de plusieurs champs ne respecte pas la deuxième forme normale si un ou plusieurs des autres champs ne dépendent pas entièrement de la clé.
Ainsi, une table avec ces champs ne respecterait pas la seconde forme normale, car l'attribut « nom produit » dépend de l'ID produit, mais pas du numéro de commande.
-
Numéro de commande (clé primaire)
-
Identifiant du produit (clé primaire)
- Nom du produit
La troisième forme normale (3NF) ajoute à ces règles la nécessité que chaque colonne non-clé soit indépendante de toutes les autres colonnes. Si la modification d'une valeur dans une colonne non-clé change une autre valeur, cette table ne correspond pas à la troisième forme normale.
Cela vous empêche de stocker des données dérivées dans la table, comme la colonne « taxe » ci-dessous, qui dépend directement du montant total de la commande :
| Commande | Montant | Taxe |
| 14325 | 40,99 $ | 2,05 $ |
| 14326 | 13.73 $ | 0,69 $ |
| 14327 | 24,15 $ | 1,21 $ |
D'autres formes de normalisation ont été proposées, notamment la forme normale Boyce-Codd, les formes normales 4 à 6, et la forme normale domaine-clé, mais les trois premières sont les plus courantes.
Ces formes expliquent les meilleures pratiques à appliquer de manière générale, mais le degré de normalisation dépend du contexte de la base de données.
Données multidimensionnelles
Certains utilisateurs veulent pouvoir accéder à plusieurs dimensions d'un certain type de données, particulièrement dans le cas des bases de données OLAP. Par exemple, ils peuvent vouloir connaître les ventes par client, par région ou par mois. Dans ce cas, le mieux est de créer une table centrale à laquelle les tables client, région et mois peuvent se référer, comme ceci :

Règles d'intégrité des données
Vous devez aussi configurer votre base de données pour qu'elle valide les données selon les règles appropriées. De nombreux systèmes de gestion de base de données, comme Microsoft Access, appliquent certaines de ces règles automatiquement.
La règle d'intégrité des entités stipule que la clé primaire ne peut jamais être NULL. Si la clé est composée de plusieurs colonnes, aucune d'elles ne peut être NULL. Sinon, elle ne pourrait pas identifier de manière unique chaque enregistrement.
La règle de l'intégrité référentielle exige que chaque clé étrangère listée dans une table corresponde à une clé primaire de la table à laquelle elle se réfère. Si la clé primaire change ou est supprimée, ces modifications devront être répercutées partout où cette clé est référencée dans la base de données.
Les règles d'intégrité de la logique métier permettent de garantir que les données correspondent à certains paramètres logiques. Par exemple, une heure de rendez-vous doit se situer pendant les horaires de bureau.
Ajout d'index et de vues
Un index est une copie triée d'une ou plusieurs colonnes, dont les valeurs ont été classées en ordre croissant ou décroissant. L'ajout d'un index permet aux utilisateurs de trouver des enregistrements plus rapidement. Au lieu de répéter le tri pour chaque requête, le système peut ainsi accéder aux enregistrements dans l'ordre spécifié par l'index.
Bien que les index accélèrent la récupération des données, ils peuvent aussi ralentir l'insertion, la mise à jour et la suppression, car l'index doit être recréé à chaque fois qu'un enregistrement est modifié.
Une vue est tout simplement une requête enregistrée sur les données. Elle peut relier utilement des données provenant de plusieurs tables ou encore montrer une partie d'une table.
Propriétés étendues
Une fois la configuration de base terminée, vous pouvez affiner la base de données avec des propriétés étendues, comme du texte d'instruction, des masques de saisie et des règles de formatage applicables à un schéma , une vue ou une colonne. Ces règles étant stockées dans la base de données elle-même, la présentation des données sera cohérente dans les multiples programmes qui accèdent aux données.
SQL et UML
Le langage de modélisation unifié (UML) est un autre moyen visuel d'exprimer des systèmes complexes créés dans un langage orienté objet. Plusieurs des concepts mentionnés dans ce guide sont connus dans UML sous des noms différents. Par exemple, une entité est appelée classe dans le langage UML.
De nos jours, le langage UML n'est plus aussi utilisé qu'auparavant. Son utilisation est aujourd'hui plus théorique et il sert souvent dans les communications entre les concepteurs de logiciels et leurs clients.
Systèmes de gestion de bases de données
Bon nombre des choix de design que vous ferez dépendront du système de gestion de base de données que vous utilisez. Les systèmes les plus courants sont :
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Lorsque vous le pouvez, basez notamment votre choix sur le coût, les systèmes d'exploitation pris en charge et les fonctions proposées.
Modélisation des données et modèles de bases de données
Un modèle de base de données illustre la structure logique d'une base de données, y compris les relations et les contraintes qui déterminent comment les données peuvent être stockées et accessibles. Les modèles de base de données individuels sont conçus en fonction des règles et concepts du modèle de données plus général adopté par les concepteurs. La plupart des modèles de données peuvent être représentés par un diagramme de base de données.
Types de modèles de bases de données
Il existe de nombreux types de modèles de bases de données. Parmi les plus courants :
- Modèle de base de données hiérarchique
- Modèle relationnel
- Modèle réseau
- Modèle de base de données orientée objet
- Modèle entité-association
- Modèle document
- Modèle entité-attribut-valeur
- Schéma en étoile
- Le modèle relationnel-objet, qui associe les deux éléments qui composent son nom
Vous pouvez choisir de représenter une base de données selon l'un de ces modèles en fonction de plusieurs facteurs. Le plus important est de savoir si le système de gestion de base de données que vous utilisez prend en charge un modèle particulier. En effet, la plupart sont pensés pour un modèle de base de données particulier et exigent des utilisateurs qu'ils adoptent ce modèle, mais certains prennent en charge plusieurs modèles.
En outre, tous les modèles ne s'appliquent pas à toutes les étapes du processus de conception d'une base de données. Les modèles de bases de données conceptuelles généralistes sont les plus indiqués pour cartographier les relations entre les données de façon à faciliter la compréhension de ces données. Les modèles logiques basés sur les enregistrements sont eux davantage axés sur la manière dont les données sont stockées sur le serveur.
Vous devez également choisir un modèle dont les points forts correspondent à vos priorités pour la base de données, que ces priorités soient la rapidité, la réduction des coûts, la simplicité d'utilisation ou autre chose.
Examinons de plus près certains des modèles de bases de données les plus courants.
Modèle relationnel
Le modèle le plus courant, appelé modèle relationnel, trie les données dans des tables, que l'on appelle aussi des relations, dont chacune se compose de colonnes et de lignes. Chaque colonne contient un attribut de l'entité en question, comme le prix, le code postal ou la date de naissance. L'ensemble des attributs d'une relation est appelé domaine. La clé primaire est constituée par un attribut spécifique ou une combinaison d'attributs. On peut y faire référence dans d'autres tables : elle est alors appelée clé étrangère.
Chaque ligne, également appelée tuple, comprend des données sur une instance spécifique de l'entité en question, comme un employé en particulier.
Le modèle tient également compte des types de relations entre ces tables, notamment les relations un-à-un, un-à-plusieurs et plusieurs-à-plusieurs. Voici un exemple :

Dans la base de données, les tables peuvent être normalisées ou amenées à se conformer aux règles de normalisation dans une optique d'amélioration de sa flexibilité, de sa polyvalence et de son évolutivité. Dans une base de données normalisée, chaque donnée est atomique, ou éclatée en morceaux utiles les plus petits possible.
Les bases de données relationnelles sont généralement écrites en langage SQL (Structured Query Language). Ce modèle a été introduit en 1970 par E.F. Codd.
Modèle hiérarchique
Le modèle hiérarchique organise les données dans une structure arborescente, où chaque enregistrement dispose d'un seul parent (racine). Les enregistrements frères et sœurs sont triés dans un ordre particulier. Cet ordre est suivi pour le stockage physique de la base de données. Ce modèle convient à la description de nombreuses relations du monde réel.

Il a surtout été utilisé par les systèmes de gestion d'information d'IBM dans les années 60 et 70, qui ont aujourd'hui majoritairement disparu en raison de certaines inefficacités opérationnelles.
Modèle réseau
Le modèle réseau est une extension du modèle hiérarchique qui autorise des relations plusieurs-à-plusieurs entre des enregistrements liés, ce qui implique plusieurs enregistrements parents. Basé sur la théorie mathématique des ensembles, ce modèle s'articule autour d'ensembles d'enregistrements connexes. Chaque ensemble se compose d'un enregistrement propriétaire (ou enregistrement parent) et d'un ou plusieurs enregistrements membres (ou enfants). Un enregistrement peut être un membre ou un enfant dans plusieurs ensembles, ce qui permet à ce modèle de traduire des relations complexes.
Son pic de popularité remonte aux années 70, après qu'il a été officiellement défini par la conférence sur les langages de systèmes de traitement de données (Conference on Data Systems Languages, CODASYL)

Modèle de base de données orientée objet
Ce modèle définit une base de données comme une collection d'objets, ou d'éléments logiciels réutilisables, associés à des caractéristiques et des méthodes. Il existe plusieurs types de bases de données orientées objet :
Une base de données multimédia réunit des médias, tels que des images, qui ne peuvent pas être stockés dans une base de données relationnelle.
Une base de données hypertextuelle permet à n'importe quel objet d'être relié à un autre. Elle est utile pour organiser de nombreuses données disparates, mais peu adaptée à l'analyse numérique.
Le modèle de base de données orienté objet est le modèle de base de données post-relationnelle le plus connu, car il intègre des tables, sans toutefois s'y limiter. Ces modèles sont aussi connus sous le nom de modèles de bases de données hybrides.

Modèle relationnel-objet
Ce modèle de base de données hybride associe la simplicité du modèle relationnel à certaines des fonctionnalités avancées du modèle de la base de données orientée objet. En substance, il permet aux concepteurs d'intégrer des objets dans la structure bien connue des tables.
Les langages et interfaces d'appel comprennent SQL3, les langages des fournisseurs, ODBC, JDBC et les interfaces d'appel propriétaires qui sont des extensions des langages et des interfaces utilisés par le modèle relationnel.
Modèle entité-association
Ce modèle reproduit les relations entre les entités du monde réel de façon très similaire au modèle réseau, mais il n'est pas lié aussi directement à la structure physique de la base de données. Il est souvent utilisé pour la création d'une base de données d'un point de vue conceptuel.
Ici, les personnes, les lieux et les objets à propos desquels les points de données sont stockés sont appelés entités, chacune d'entre elles possédant certains attributs qui, ensemble, composent leur domaine. On schématise aussi la cardinalité (relations entre les entités).

L'une des formes courantes du diagramme entité-association est le schéma en étoile, dans lequel une table centrale des faits se connecte à plusieurs tables dimensionnelles.
Autres modèles de bases de données
Divers autres modèles de bases de données ont été ou sont encore utilisés aujourd'hui.
Modèle de fichier inverséUne base de données créée selon une structure de fichier inversé est conçue pour accélérer les recherches en texte intégral. Dans ce modèle, le contenu des données est indexé sous la forme d'une série de clés dans une table de recherche, dont les valeurs indiquent l'emplacement des fichiers associés. Cette structure peut fournir des rapports quasi instantanés dans le domaine des Big Data ou de l'analytique, par exemple.
Ce modèle est utilisé par le système de gestion de base de données ADABAS de Software AG depuis 1970, et il est encore pris en charge aujourd'hui.
Modèle de base de données orientée texteLe modèle de base de données orientée texte est le plus ancien et le plus simple. Il énumère simplement toutes les données dans une seule table, composée de colonnes et de lignes. Pour accéder aux données ou les manipuler, l'ordinateur doit lire l'intégralité du fichier plat dans la mémoire, ce qui rend ce modèle inefficace, sauf pour les ensembles de données les plus petits.
Modèle multidimensionnelIl s'agit d'une variante du modèle relationnel conçue pour améliorer le traitement analytique. Alors que le modèle relationnel est optimisé pour le traitement transactionnel en ligne (OLTP), ce modèle est conçu pour le traitement analytique en ligne (OLAP).
Chaque cellule d'une base de données dimensionnelle contient des données sur les dimensions suivies par la base de données. Visuellement, elle ressemble à un ensemble de cubes plutôt qu'à des tables en deux dimensions.
Modèle semi-structuréDans ce modèle, les données structurelles habituellement contenues dans le schéma de base de données sont intégrées aux données elles-mêmes. La distinction entre les données et le schéma est donc pour le moins vague. Ce modèle est utile pour décrire les systèmes, comme certaines sources de données sur le Web, que l'on traite comme des bases de données, mais qui ne peuvent pas s'adapter à un schéma. Il est également utile pour décrire des interactions entre des bases de données qui ne respectent pas le même schéma.
Modèle contextuelCe modèle peut incorporer des éléments provenant d'autres modèles de bases de données selon les besoins. Il réunit des éléments des modèles orienté objet, semi-structuré et réseau.
Modèle d'associationCe modèle divise tous les points de données selon qu'ils décrivent une entité ou une association. Dans ce modèle, une entité désigne tout élément qui existe de façon indépendante, alors qu'une association désigne tout élément qui n'existe que par rapport à un autre élément.
Le modèle d'association structure les données en deux ensembles :
- Un ensemble d'éléments, chacun ayant un identificateur unique, un nom et un type
- Un ensemble de liens, chacun ayant un identificateur unique et les identificateurs uniques d'une source, d'un verbe et d'une cible. Le fait stocké est en lien avec la source, et chacun des trois identificateurs peut faire référence soit à un lien, soit à un élément.
Parmi les autres modèles de bases de données moins courants :
- Le modèle sémantique, qui comprend des informations sur la façon dont les données stockées sont rattachées au monde réel
- La base de données XML, qui permet aux données d'être spécifiées et même stockées au format XML
- Le graphe nommé
- Le triplestore
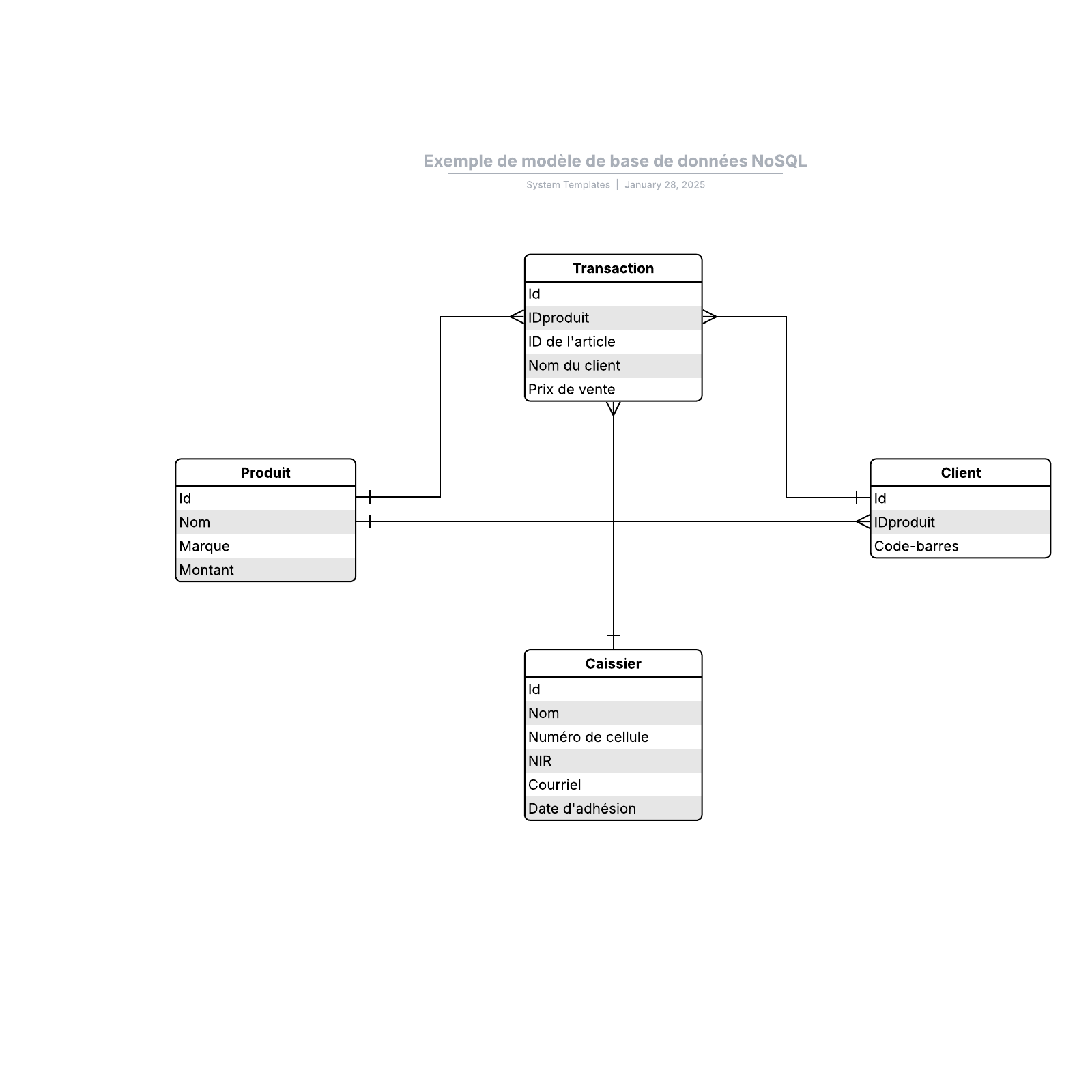
Modèles de bases de données NoSQL
Outre le modèle de base de données orienté objet, d'autres modèles non SQL sont venus s'opposer au modèle relationnel :
Le modèle de base de données orienté graphe, qui est encore plus flexible qu'un modèle réseau, car il permet la connexion entre tous les nœuds, quels qu'ils soient.
Le modèle multivaleur, qui se distingue du modèle relationnel en permettant aux attributs de contenir une liste de données plutôt qu'un seul point de données.
Le modèle orienté document, qui est conçu pour stocker et gérer des documents ou des données semi-structurées plutôt que des données atomiques.
Bases de données sur le Web
La plupart des sites Web s'appuient sur un type de base de données pour organiser et présenter des données aux utilisateurs. Chaque fois qu'un visiteur utilise les fonctions de recherche sur ces sites, ses termes de recherche sont transformés en requêtes qu'un serveur de base de données va traiter. En règle générale, un middleware (ou intergiciel) connecte le serveur Web à la base de données.
L'omniprésence des bases de données leur permet d'être utilisées dans presque tous les domaines, des boutiques en ligne au micro-ciblage d'un segment des électeurs dans le cadre d'une campagne politique. Divers secteurs ont développé leurs propres normes pour la conception de bases de données, des transports aériens aux constructeurs automobiles.